As we transition towards the vast quantity of devices that will be internet enabled by 2020, (anything from 50-200 billion experts estimate), it seems that the current cloud architectures that are being proposed are somewhat short on the features required to enable the customers data requirements on 2020.
I wont dive hugely into describing the technology stack of a Data Lake in this post (Ben Greene from Analytics Engines in Belfast, who I visit on Wednesday en route to Enter Conf, does a nice job here of that in his blog here). A quick side step, if you look at the Analytics Engines website, I saw that customer choice and ease of use were some of their architecture pillars, when providing their AE Big Data Analytics Software Stack. Quick to deploy, modular, configurable with lots of optional high performance appliances. Its neat to say the least, and I am looking forward to seeing more.
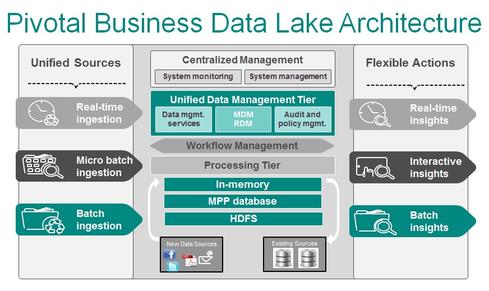
The concept of a Data Lake has a large reputation in current tech chatter, and rightly so. Its got huge advantages in enterprise architecture scenarios. Consider the use case of a multinational company, with 30,000+ employees, countless geographically spread locations, multiple business functions. So where is all the data? Its normally a challenging question, with multiple databases, repositories and more recently, hadoop enabled technologies storing the companies data. This is the very reason why a business data lake (BDL) is a huge advantage to the corporation. If a company has a Data Architect at its disposal, then it can develop a BDL architecture (such as shown below, ref – Pivotal) that can be used to act as a landing zone for all their enterprise data. This makes a huge amount of sense. Imagine being the CEO of that company, and as we see changes in the Data Protection Act(s) over the next decade, a company can take the right step towards managing, scaling and most importantly protecting their data sets. All of this leads to a more effective data governance strategy.
Now shift focus to 2020 (or even before?). And lets take a look at the customer landscape. The customers that will require what the concept of a BDL now provides will need far more choice. And wont necessarily be willing to pay huge sums for that service. Now whilst there is some customer choice of today, such as Pivotal Cloud Foundry, Amazon Web Services, Google Cloud and Windows Azure, it is predicted that even these services are targeted at a consumer base of a startup and upwards in the business maturity life cycle. The vast majority of cloud services customers in the future will be everyone around us, the homes we live in and beyond. And the requirement to store data in a far distance data center might not be as critical for them. It is expect they will need far more choice.
I expect in the case of building monitoring data, which could be useful to the wider audience in a secure linked open data sets (LOD’s) topology. For example, smart grid provider might be interested in energy data from all the buildings and trying to suggest optimal profiles for them to reduce impact on the grid. Perhaps the provider might even be willing to pay for that data? This is where data valuation discussions come into play, and is outside the scope of the blog. But the building itself, or its tenants might not need to store all their humidity and temperature data for example. They might some quick insight up front, and then might choose bin that data (based on some simple protocol describing the data usage) in their home for example).
Whilst a BDL is built on the premise of “Store Everything”, it is expected that whilst that will bring value for these organisations monitoring consumers of their resources, individual consumers might not be willing to pay for this.
To close, the key enablers to these concepts are the ensure that real time edge analytics and increased data architecture choice. And this is beginning to happen. Cisco have introduced edge analytics services into their routers, and this is a valid approach to ensuring that the consumer has choice. And they are taking the right approach, as there is even different services for different verticals (Retail, IT, Mobility).
In my next blog, Edge Analytics will be the focus area, where we will dive deeper into the question. “where do we put our compute?”
